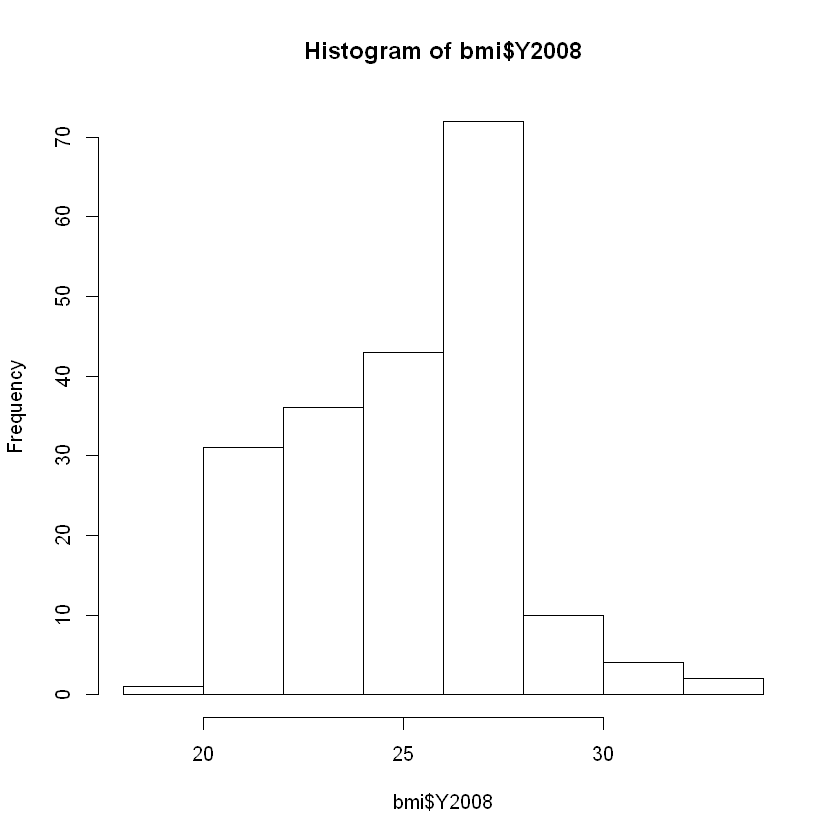
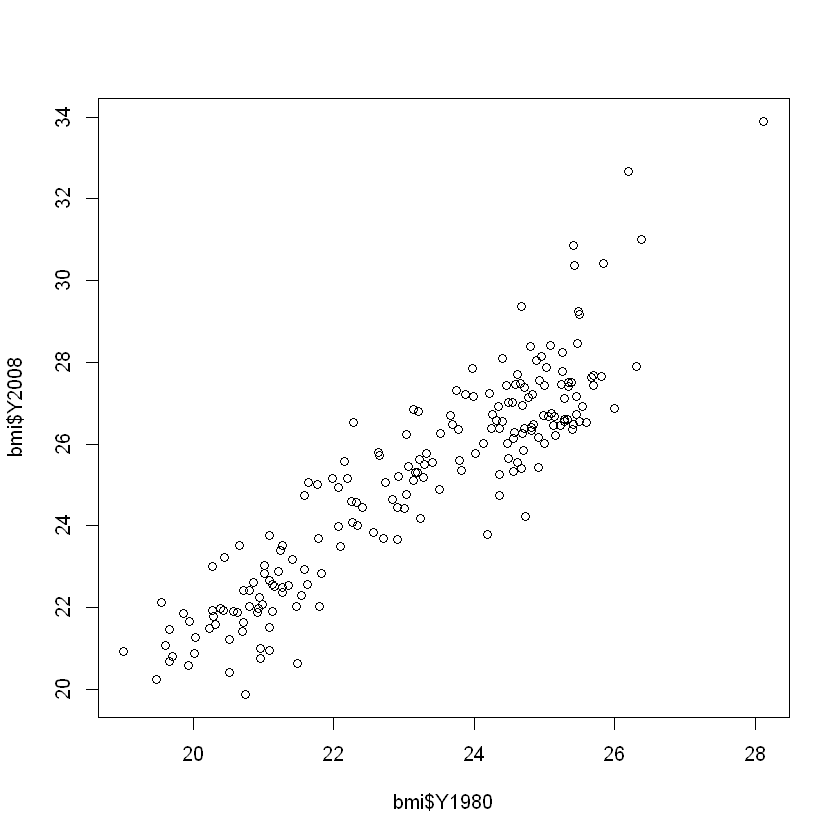
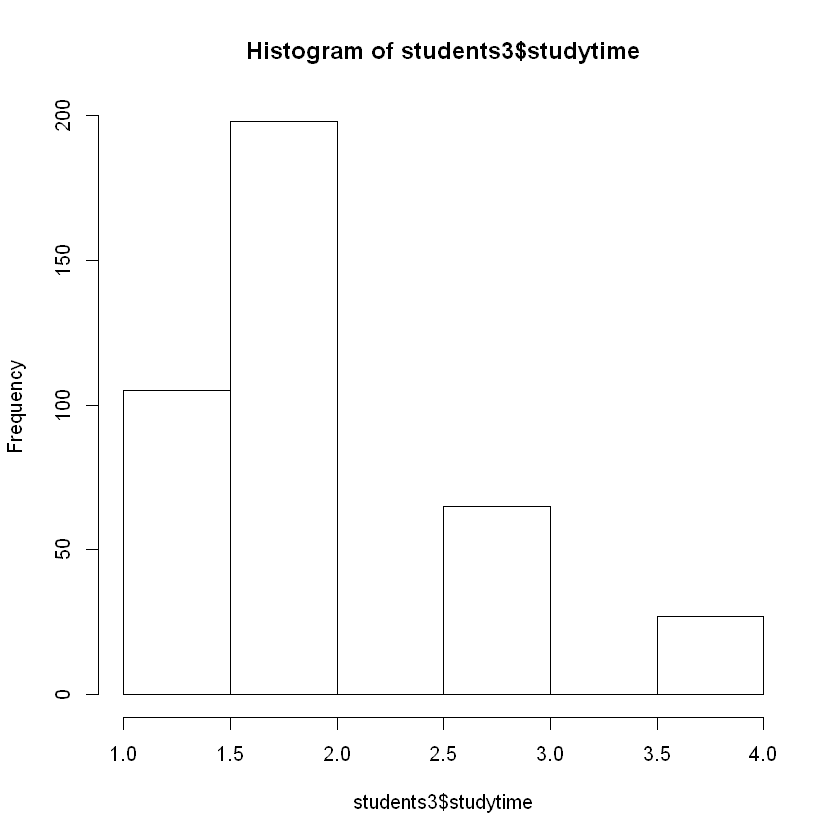
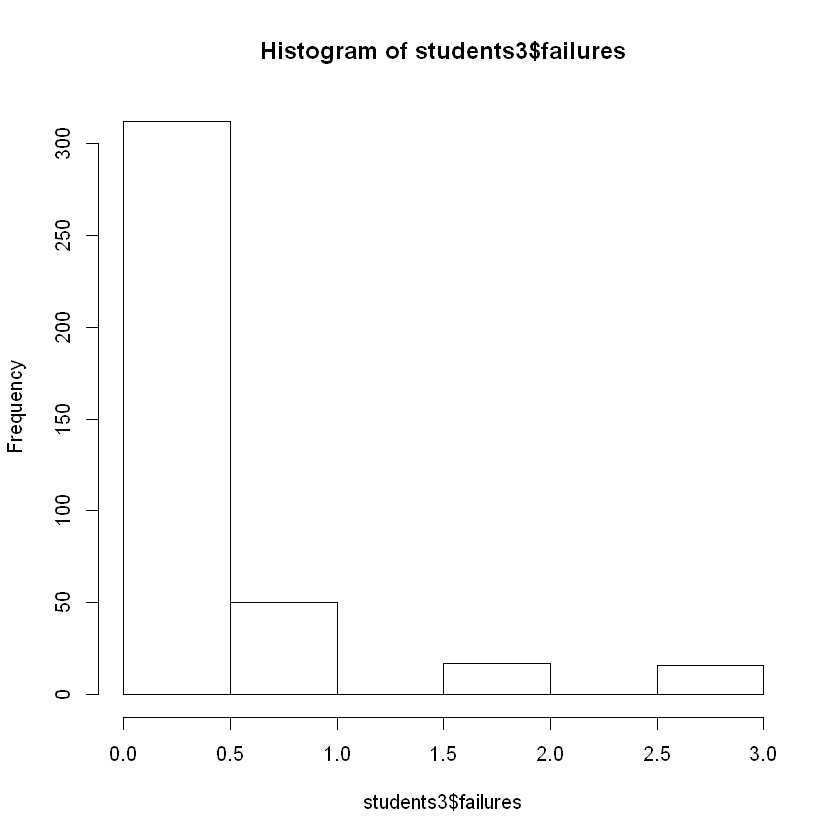
Rows: 199
Columns: 30
$ Country <chr> "Afghanistan", "Albania", "Algeria", "Andorra", "Angola", "...
$ Y1980 <dbl> 21.48678, 25.22533, 22.25703, 25.66652, 20.94876, 23.31424,...
$ Y1981 <dbl> 21.46552, 25.23981, 22.34745, 25.70868, 20.94371, 23.39054,...
$ Y1982 <dbl> 21.45145, 25.25636, 22.43647, 25.74681, 20.93754, 23.45883,...
$ Y1983 <dbl> 21.43822, 25.27176, 22.52105, 25.78250, 20.93187, 23.53735,...
$ Y1984 <dbl> 21.42734, 25.27901, 22.60633, 25.81874, 20.93569, 23.63584,...
$ Y1985 <dbl> 21.41222, 25.28669, 22.69501, 25.85236, 20.94857, 23.73109,...
$ Y1986 <dbl> 21.40132, 25.29451, 22.76979, 25.89089, 20.96030, 23.83449,...
$ Y1987 <dbl> 21.37679, 25.30217, 22.84096, 25.93414, 20.98025, 23.93649,...
$ Y1988 <dbl> 21.34018, 25.30450, 22.90644, 25.98477, 21.01375, 24.05364,...
$ Y1989 <dbl> 21.29845, 25.31944, 22.97931, 26.04450, 21.05269, 24.16347,...
$ Y1990 <dbl> 21.24818, 25.32357, 23.04600, 26.10936, 21.09007, 24.26782,...
$ Y1991 <dbl> 21.20269, 25.28452, 23.11333, 26.17912, 21.12136, 24.36568,...
$ Y1992 <dbl> 21.14238, 25.23077, 23.18776, 26.24017, 21.14987, 24.45644,...
$ Y1993 <dbl> 21.06376, 25.21192, 23.25764, 26.30356, 21.13938, 24.54096,...
$ Y1994 <dbl> 20.97987, 25.22115, 23.32273, 26.36793, 21.14186, 24.60945,...
$ Y1995 <dbl> 20.91132, 25.25874, 23.39526, 26.43569, 21.16022, 24.66461,...
$ Y1996 <dbl> 20.85155, 25.31097, 23.46811, 26.50769, 21.19076, 24.72544,...
$ Y1997 <dbl> 20.81307, 25.33988, 23.54160, 26.58255, 21.22621, 24.78714,...
$ Y1998 <dbl> 20.78591, 25.39116, 23.61592, 26.66337, 21.27082, 24.84936,...
$ Y1999 <dbl> 20.75469, 25.46555, 23.69486, 26.75078, 21.31954, 24.91721,...
$ Y2000 <dbl> 20.69521, 25.55835, 23.77659, 26.83179, 21.37480, 24.99158,...
$ Y2001 <dbl> 20.62643, 25.66701, 23.86256, 26.92373, 21.43664, 25.05857,...
$ Y2002 <dbl> 20.59848, 25.77167, 23.95294, 27.02525, 21.51765, 25.13039,...
$ Y2003 <dbl> 20.58706, 25.87274, 24.05243, 27.12481, 21.59924, 25.20713,...
$ Y2004 <dbl> 20.57759, 25.98136, 24.15957, 27.23107, 21.69218, 25.29898,...
$ Y2005 <dbl> 20.58084, 26.08939, 24.27001, 27.32827, 21.80564, 25.39965,...
$ Y2006 <dbl> 20.58749, 26.20867, 24.38270, 27.43588, 21.93881, 25.51382,...
$ Y2007 <dbl> 20.60246, 26.32753, 24.48846, 27.53363, 22.08962, 25.64247,...
$ Y2008 <dbl> 20.62058, 26.44657, 24.59620, 27.63048, 22.25083, 25.76602,...